Discuss Notion Music Composition Software here.
3 posts
Page 1 of 1

|
I prefer stereo, and I love a bit of reverberation and echoes--sometimes a lot--but not always on all the instruments and voices, at least to a level which is easily perceived . . .
Here in the sound isolation studio, reverberation, echo units, and similar space, time, and motion effects are considered to be special effects, not general effects . . . In particular, reverberation is like salt and spices in the sense that they change the taste and flavor of food and beverages . . . [NOTE: Echo and digital delay are types of reverberation, but they are considered generally to be different from reverberation, and in some respects reverberation is like the D-Day Invasion of France during the Second World War, while echo and digital delay are like platoons of soldiers . . . ] The genre is important, and to some degree it establishes the rules for producing and mixing, but you can create your own genres where the rules are different . . . It's a matter of producing and mixing, and these are different activities from composing, instrumenting, arranging, and performing . . . THOUGHTS ON REVERBERATION Among other activities, I am developing Rack Extensions for use by folks who do some or all of their musical work in Reason (Propellerhead Software); and the high-level overview is that in the Reason universe, Rack Extensions are like Virtual Studio Technology (VST) effects plug-ins, although there also are instrument Rack Extensions--mostly synthesizers--but I'm not interested in Rack Extension instruments, only in Rack Extension effects, and then primarily in space, time, and motion effects (reverberation, echoes, and pitch manipulation like vibrato but also tremolo and anything else that's interesting or potentially interesting) . . . In the Rack Extension universe, it's all about samples--but not "samples" in the sense of the sound samples of a recorded instrument at the note level . . . Instead, it's a matter of samples in the micro universe where, for example, at a sample rate of 44.1-kHz (standard CD audio quality), there are exactly 44,100 samples per second, and each sample has two parameters: (1) volume level, a real number in the range from -1.0 to 0 to +1.0 . . . (2) arrival time, which is relative rather than being a timestamp, where per second at standard CD audio quality 44,100 samples arrive in sequential order running from most recent to least recent, with everything occurring at "computer speed", which is sufficiently fast that even though the individual samples arrive in sequence over time, the computing is done so swiftly that in "wall clock" time it appears to the listener to be instantaneous; but this is an audio illusion, because at "computer speed" it's not instantaneous, at all. In fact, there is plenty of "computing time" to do a lot of mathematical manipulation (a.k.a., "number crunching"), which is done in algorithms that combine storing and retrieving numerical data and doing things with the data (a.k.a., "samples") using various mathematical formulas and so forth . . . If you watch digitally sampled audio on an oscilloscope, you can see the volume levels, but it's easier when you watch the audio run through a Fast Fourier Transform (FFT) analyzer, which examines the samples and separates them into specific frequencies and their respective volume levels . . . Arrival times are implied in a FFT analyzer, but for practical purposes it's a real-time continuous stream, so it doesn't show the arrival times for individual samples over time in a way that lets you see past and present, where for reference the virtual future is available over a short time, but it's perhaps just a millisecond or two, although technically when you create an echo you are working in the virtual future and are creating something which will be heard perhaps as much as a second or two later, but typically perhaps 5 to 500 milliseconds later, with the Haas Effect ranging from 5 to 50 milliseconds and "slapback" echo being around 125 milliseconds . . . [NOTE: This is the MOTU FFT Analyzer output for one of my Cuban Jazz compositions, which is "Cuban" because it uses the Cuban Trumpet from Native Instruments "Cuba Collection"--not because the song has anything to do with Cuban music. I call it "Jazz", because when I was high school I played String Bass in a four-piece musical group (Piano, Drums, String Bass, and Trumpet), and when we played stuff like this we called it "Jazz", but most of the time we played songs that "grown-ups" liked for dancing, which usually were songs from the 1930s and 1940s, although occasionally we did some current songs--but the "grown-ups" didn't like "teenage music", so not that often. As long as the "grown-ups" could enjoy "happy beverages" and dance, they were happy, and we got paid, so it was all good. Making it all the more surreal, the fellow who played Piano was 14 years-old, a year younger than me. Today I'm not so certain that underage teenagers would be allowed to be the house band in a nightclub that serves alcohol, but everything was different in those days, and the local police didn't care one way or the other, perhaps because in those days driver licenses were printed on paper and didn't have photos, hence were easy to modify, so to speak. As I recall, I was "22 years-old" and the Piano player was "27 years-old", since he looked older than me, but what was most surreal was the fact that he owned a house, a car, and was married . . . ] If you want to create a simple digital delay Rack Extension, then you make a copy of the incoming samples as they arrive and play-back the copied samples after a delay and mix them with the current set of incoming samples, where the delay time depends on how the user sets it, so that for example, if the desired digital delay is 25 milliseconds, then this is how much time you wait before you start playing-back the copied sample stream, so at first for 25 milliseconds all you hear is the current incoming stream of samples, but once the copied stream is "loaded" and stored in memory, you mix it with the next incoming stream of samples, and then from that time going forward you have a simple 25 millisecond delay effect, which you can vary by adjusting the dry and wet mix volume; and at this delay time, you get the Haas Effect, which curiously makes material sound louder without actually being louder--an audio perception phenomenon about which my hypothesis is that it's a Darwinian survival skill which makes certain rapidly occurring sounds more prevalent, like the paws of a bear or tiger hitting the ground . . . If you vary the delay time quickly within a small timeframe, this creates vibrato, which continues to be something that for me is as fascinating as it is mysterious . . . I understand it mathematically, but it's different from what happens when one is dealing with notes and music notation, primarily because notes and music notation happen at a higher level than individual digital samples . . . For example, a quarter note at a tempo of 220 beats per minute maps to a dry duration of approximately 0.27 seconds, and this maps approximately to 12,207 samples at standard CD audio quality . . . Conceptually, a quarter note makes sense to me, but the concept that 12,207 samples is a quarter note is not so intuitive, and it's taking a while for this mapping to make intuitive sense, but I'm working on it and making a bit of progress . . . It's a bit like conceptualizing a house not as a set of rooms with floors, walls, and ceilings but instead as a collection of molecules . . . Building material is molecules, and molecules have atoms, but that's a completely different perspective from working with lumber, bricks, sheetrock, glass, and so forth . . . How does this pertain to reverberation? Great question! If you are designing and programming digital reverberation, then it's like a complex set of simple delay algorithms combined with frequency filters and lots of other stuff--all of which require intensive computing--but another way to do it is to have sets of room measurement data, which you use instead of an elaborate set of recursive simple delay algorithms and filters; and this is what a "convolution" reverberation algorithm does . . . The data set for the behavior of the room is collected in much the same way as musical instruments are recorded and then digitized to create sampled sound libraries, but instead of recording a musician playing individual notes on an instrument in a room, what happens is that a machine is used to create short bursts of pink noise or some type of full-range noise, and the behavior of the "noise" in the room then is recorded over time; and this captures the acoustic behaviors of the room over time . . . Once you have that data set, you can use it as a type of filter or template through which you run the incoming stream of instrument samples with the result that the output of the convolution reverb algorithm sounds like the instrument is being played or the singer is singing in the room you sampled to get its acoustic behaviors over time; and this is done because it requires considerably less processing than doing everything with a set of individual algorithms (or a combination of simple delay algorithms and simple frequency filter algorithms, some of which usually are a bit recursive by design) . . . This is an example of a classic reverberation algorithm drawn in block style: 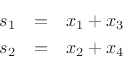 [SOURCE: Schroeder Allpass Sections (``Physical Audio Signal Processing'', by Julius O. Smith III, W3K Publishing, 2010, ISBN 978-0-9745607-2-4. Center for Computer Research in Music and Acoustics [CCRMA], Stanford University) ] I can do a bit of mathematics, but (a) there are levels to all this stuff and (b) in a Rack Extension there are limits to the amount of computing that can be done within the "window of opportunity" available where all the computing is started and finished in sufficient time for the resulting audio to appear to a human listener to be "in real-time" . . . In other words, you can't run an algorithm that takes hours to complete and then expect it to be of any use as a virtual real-time digital effect, hence the strategy to take a "snapshot" of the room over a reasonable amount of time and then to use it effectively as a "template" or "cookie cutter" to transform dry audio into wet audio . . . [i[I can't compute curl, but I can visualize it . . . [/i]  [SOURCE: Curl (Mathematics) ~ Wikipedia ] On the algorithmic side of reverberation, I have a fascinating effects plug-in called "Panorama 3D" (Wave Arts), and it's very nice but it does a lot of computing, so (a) it can't be used on each separate instrument or voice in a practical way and (b) it's like whammying in the sense that it requires a lot of empty sonic space for the reverberation to provide the audio cues necessary to affect spatial sound perception--the audio perception that determines sound source location--so while Panorama 3D is fascinating, it's only practical for very specialized tasks that allow a lot of empty sonic space . . . Panorama 3D changes the tonal and spatial characteristics of dry audio, but Panorama 3D does it primarily by algorithms . . . Regardless of the way the reverberation is done, these types of effects make significant changes to the raw audio; and my perspective is that this can be problematic, especially when it's done for each individual instrument or voice . . . Remember that even when the raw sound samples are done in a recording studio--as contrasted to a concert hall--there always is a bit of reverberation, unless this is done in an anechoic chamber, which is unlikely . . .  In other words, there already is reverberation present in the raw sound samples, and at least for purposes of virtual realism the rule tends to be that a little bit of reverberation goes a long way . . . [NOTE: The corollary to this rule is that when reverberation goes beyond a long way, it's a special effect rather than a general effect . . . ] The extreme in this instance is the Taj Mahal, which has so much natural reverberation that the general perspective is that it becomes nearly impossible to conduct a conversation with someone standing just a few feet away without resorting to screaming or using sign language . . . I have a friend who has a large swimming pool in a metal building with large glass windows and no sound absorbing material, at all, other than perhaps a few chairs with cushions and some cotton towels . . . It's not exactly the Taj Mahal, but having a conversation requires shouting, even when the people are just a few feet away from each other . . . At some time, I want to put a guitar amplifier and some microphones in the swimming pool building and use it as a reverb chamber, which is one way reverb chambers were created back in the days before digital circuitry and computers, where the strategy was to use a large ceramic tiled room, perhaps with a swimming pool or some type of water surface, and then to have a loudspeaker for the "raw" audio and some microphones, either in fixed locations or mounted in some way on motorized platforms or cable wires so the microphones could be moved in relation to the loudspeaker to adjust the "depth" of the reverberation . . . Yet another way was to use a large metal plate in high tension, and this is the type of reverberation that was used on Elvis Presley's vocals a while after the Sun Recording Studio days--basically when he recorded for RCA--and this type of physical reverberation unit produces very nice reverberation . . . [NOTE: Elvis was superbly skilled in "working" a condenser microphone, compressor-limiter, and plate reverb, which he did by controlling the volume of his voice and the distance from the condenser microphone. This recording is best enjoyed when listening with studio quality headphones like the SONY 7506 (a personal favorite), since it's easiest to hear the condenser microphone, compressor/limiter, and plate reverb being "worked"; and by the time Elvis recorded this song, he had plenty of recording experience and knew how to "work" a condenser microphone, compressor/limiter, and plate reverb . . . ] It's all potentially good, but I think it helps to hear Elvis without any effects (compressing, limiting, reverberation, slap-back echoes, and so forth) when you expect to do the best producing and mixing . . . And there are additional techniques that make sense when working with reverberation, where one of the techniques used at Abbey Road Studios for the Beatles was to pre-filter the raw audio before sending it to the reverberation units, and this pre-filtering removed the audio material below approximately 500-Hz or 600-Hz and above 10,000-Hz, since (a) running low and mid-range audio material through reverberation units just made everything muddy and (b) running material above 10,000-Hz provided no useful results and overall tended to introduce annoying high-frequency noise, which of course wanders into a different aspect of the Gestalt, which specifically is that while the generally accepted range of "normal" human hearing runs from 20-Hz to 20,000-Hz, few people other than children hear much of anything higher than perhaps 13,000-Hz, which makes most folks a bit like reverberation units, at least in the sense that anything above 10,000-Hz becomes noise and serves no useful purpose, which is another troubling aspect of both convolution reverb and algorithmic reverb, at least when there are no filters to exclude the troublesome frequency ranges . . . Yet another bit of relative information comes from Les Paul and his experience recording, producing, and mixing, where his rule was that putting reverberation on individual instruments tended to be less effective and real than putting reverberation on the mix of everything, with the logic being that each musician and singer is not in their own unique room with different acoustic behaviors, hence don't produce them that way, because it's unnatural . . . [NOTE: There are obvious exceptions, such as drum booths and vocal booths, but so what . . . ] Instead, use reverberation on the mix of all the instruments to achieve the goal of having the instruments, singers, and ensemble or group sound like they are performing together in a room, even though each one is recorded separately, which generally is the case with sampled sound libraries--except for sampled groups of instruments, of course . . . It's like connecting the loudspeaker input wires for a pair of loudspeakers used for stereo listening . . . If the speaker wires are connected correctly, then everything is fine; but if one pair of loudspeaker wires is reversed (which is incorrect), then there is a frequency canceling phase affect which is noticeable once you do a bit of experimenting and train your "ears" . . . This is one of the reasons for doing an occasional bit of monaural listening, since something similar can occur; and the "easy" way to check for this is to listen to a stereo mix in monaural mode . . . This YouTube video explains Fast Fourier Transforms (FFT) and other related acoustic physics stuff in an excellent way, and it shows how sine waves can be used to create square waves and sawtooth waves, which with the native NOTION instruments often is too easy and tends to make the otherwise very nice sampled instruments sound more like a 1960s Farfisa Compact Organ . . . [NOTE: This explanation of waveforms and frequencies provides stellar insights into what happens mathematically when one is instrumenting, producing, and mixing; and it also provides a few clues to one of Joseph Schillinger's (System of Musical Composition [SoMC]) hypotheses that songs are inspired ideas that spiral to us from the heavens, which is a bit metaphysical but tends to make sense when you ponder it for a while, especially considering there's plenty of documented evidence that "songs just appear" in the minds of composers, where the kernel or basic structure and melody arrive quickly, almost magically or perhaps divinely . . . ] "The Mathematical Basis of the Arts" (Joseph Schillinger) ~ University of Michigan ] "The Schillinger System of Musical Composition" "The thesis underlying Schillinger's research is that music is a form of movement. Any physical action or process has its equivalent form of expression in music. Both movement and music are understandable with our existing knowledge of science. His contribution was intuitively recognizing how to apply everyday mathematics to the making of music. He expressed the belief that certain patterns were universal, and common to both music and the very structure of our nervous system." [SOURCE: Schillinger System(Wikipedia) ] [NOTE: I want this fellow in my band! ] Lots of FUN!
Surf.Whammy's YouTube Channel
The Surf Whammys Sinkhorn's Dilemma: Every paradox has at least one non-trivial solution! |
|
Thanks Surf Whammy! The last vid is a perfect icing on your post (the cat beautifully crescendoes the growing surreal vein). I love your cognitive universe and your longish posts propelled and scaffolded by imaginative/eccentric associations. Reading you I am sometimes reminded of the writings of N N Taleb.
Fabulous, really! |
rehaartan wroteThanks Surf Whammy! The last vid is a perfect icing on your post (the cat beautifully crescendoes the growing surreal vein). I love your cognitive universe and your longish posts propelled and scaffolded by imaginative/eccentric associations. Reading you I am sometimes reminded of the writings of N N Taleb. Glad you enjoyed it! And special thanks for the gracious words and turning me onto N. N. Taleb, whose thinking appears to match my thinking regarding the market, which is another favorite activity to which I devote nearly as much time as (a) composing, recording, and producing music and (b) obsessive-compulsive lawn mowing . . . "Grass grows; lawns need to be mowed." I want to read Taleb's books, for sure . . . Lots of FUN! P. S. I did a new mix for "Syrup" (The Surf Whammys), which now is done with NOTION 6 and mixed in Digital Performer 9 (MOTU) . . . [NOTE: This is a headphone mix, so it's best enjoyed with listening with headphones . . . ] I think this is a good example of having a bit of FUN with reverberation, echoes, space, time, and motion . . . It's just seven instruments and some Latin percussion, but the reverberation, echoes, space, time, and motion effects reveal hidden counterpoint and harmonies and by doing so transform the sonic listening experience, thereby making it a Gestalt for which the whole is more than the sum of its parts, which is fabulous . . . Fabulous!
Surf.Whammy's YouTube Channel
The Surf Whammys Sinkhorn's Dilemma: Every paradox has at least one non-trivial solution! |
3 posts
Page 1 of 1
Who is online
Users browsing this forum: No registered users and 8 guests